YFCC100M和SUN3D数据集提取代码分析
YFCC100M和SUN3D数据集提取代码分析
一、数据集结构
1.字段
1)’xs’:初始匹配对的归一化平面坐标:

2)’ys’:通过相机外参计算得到基础矩阵,然后计算所有匹配对在基础矩阵作用下偏差。正确的匹配对有如下关系:
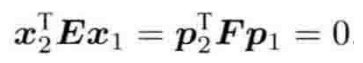
如果不是正确匹配对的话,在基础矩阵F作用下值不为0,实际的代码中最后的结果进行了平方操作和归一化操作,所以ys的值全部是大于等于0的。
3)’Rs’:两个图像对的相对旋转矩阵
4) ‘ts’:两个图像对的相对平移向量
5)’ratios’:计算描述子相似度时,每个特征点与其他特征点的描述符之间最小的欧式距离和第二小的欧式距离之比
6) ‘mutuals’:是否互为最匹配点
7) ‘cx1s’:表示图像1坐标原点到像素坐标原点在x轴方向的位移(单位为像素),图像坐标原点默认在图像中心,而像素坐标原点在左上角
8)’cy1s’:表示图像1坐标原点到像素坐标原点在y轴方向的位移(单位为像素),图像坐标原点默认在图像中心,而像素坐标原点在左上角
9)’f1s’:表示图像1的两个相机内参$f_x$和$f_y$,其中 $f_x$= $\alpha f$,其中$\alpha$是图像坐标系x轴每单位代表的像素数,$f$表示焦距,$f_y$同理。
10)’cx2s’:表示图像2坐标原点到像素坐标原点在x轴方向的位移(单位为像素),图像坐标原点默认在图像中心,而像素坐标原点在左上角
11)’cy2s’:表示图像2坐标原点到像素坐标原点在y轴方向的位移(单位为像素),图像坐标原点默认在图像中心,而像素坐标原点在左上角
12)’f2s’:表示图像2的两个相机内参$f_x$和$f_y$,其中 $f_x$= $\alpha f$,其中$\alpha$是图像坐标系x轴每单位代表的像素数,$f$表示焦距,$f_y$同理。
二、代码执行总体流程
1.提取特征点和对应的描述子
1 | |
会为每张图片生成一个hdf5文件(类似字典格式),文件里面存储的是该图片的所有特征点[‘kepoints’]及其描述子[‘descriptors’]
2.生成dataset
1 | |
调用过程
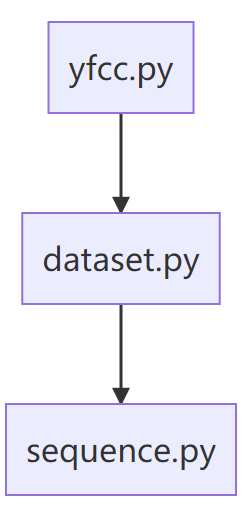
2.1.构建图片对
在sequence.py文件中的Sequence类初始化过程中构建(dataset.py—>self.dump_data()–>dataset=Sequence())。在每个场景的图片中根据visibility.txt中的能见度阈值挑选出能见度大于指定阈值(50)的图片进行两两配对。在每个场景中随机选取指定数量的图片对。
2.2.特征点匹配
dataset.py—>self.dump_data()–>dataset=Sequence()–>dataset.dump_intermediate()
构建完图片对后,对每个图片对的特征点采用最近邻算法进行特征点匹配。得到idx_sort、ratio_test、mutual_nearest,存储到h5文件中。
idx_sort:包含两个数组,第一个数组为图片1中特征点编号,第二个数组为与图片1特征点最近的图片2的特征点编号

mutual_nearest:表示是否是互最近邻的数组,0代表不是互最近邻,1代表是互最近邻
ratio_test:最近邻与次近邻欧式距离比
2.3.保存数据
dataset.py—>self.dump_data()–>dataset=Sequence()–>dataset.dump_datasets()
通过self.make_xy()接口来获取需要的字段信息。
所有字段信息分开保存为pkl文件,比如xs字段,每个场景保存一个xs.pkl文件
2.4.所有场景的数据存入一个h5py文件中
dataset.py—>self.dump_data()–>self.collect()
h5py文件结构

每个group代表一个字段,group里面的每个dataset表示每对图片对的字段信息
三、代码结构
1.代码文件
extract_feature.py:通过SIFT算法提取特征点和对应的描述子,生成hdf5文件存储每张图片的所有特征点和对应的描述子
yfcc.py:生成yfcc100m的训练集、测试集和验证集
dataset.py:被yfcc.py调用,用于生成dataset
geom.py:处理相机内外参的接口,被sequence.py调用
transformations.py:被geom.py调用,用于处理四元数
sequence.py:提取图像对,计算图像对的相对的相机外参